通过kimuraframework的项目模式抓取网页信息,并存入json文件
准备工作
安装
建议使用最新版本,bug相对比较少
gem install kimurai -v 1.4.0
创建项目
kimurai generate project web_spiders
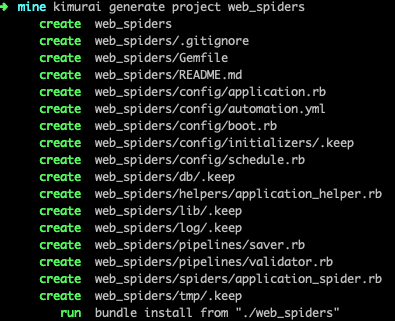
创建爬虫
cd web_spiders
kimurai generate spider zimuzu

查看爬虫列表
kimurai list
=> zimuzu
调试
在正式写爬虫之前,需要对列表页及详情页的元素定位进行调试,用kimurai console模式非常方便,我们以字幕组的影视库页面为例子。
console模式
kimurai console --engine selenium_chrome --url http://www.zimuzu.io/resourcelist
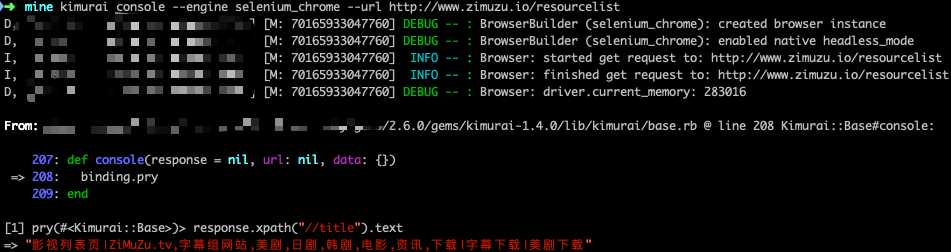
列表页
需要获取详情页链接和下一页按钮的链接。
详情页链接
response.xpath('//div[@class="resource-showlist has-point"]/ul/li/div[@class="fl-info"]/dl/dt/h3/a').map { |e| e[:href] }
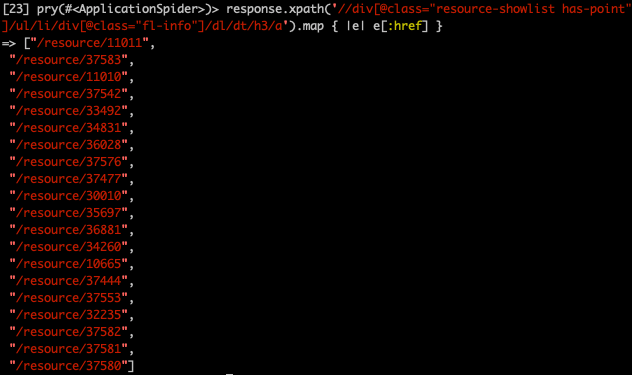
下一页链接
response.xpath('//div[@class="pages"]/div/a').search("[text()*='下一页']")[0][:href]

详情页
找一个数据饱满的页面做调试,尝试获取一下内容。
kimurai console --engine selenium_chrome --url http://www.zimuzu.io/resource/32235
缩略图
response.xpath("//div[@class='imglink']/a/img").attr('src').value

标题
标题元素的标签不太规范,需要额外处理下
response.xpath("//div[@class='resource-tit']/h2").children.first.text.gsub("【美剧】", "").strip

类型
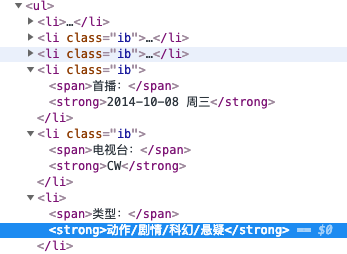
由于li的栏目可能因为空而不显示,所以寻找“类型:”元素的下一个元素。
array = response.xpath("//div[@class='fl-info']/ul/li").children.map(&:text)
categories = array[array.index("类型:") + 1].split("/")
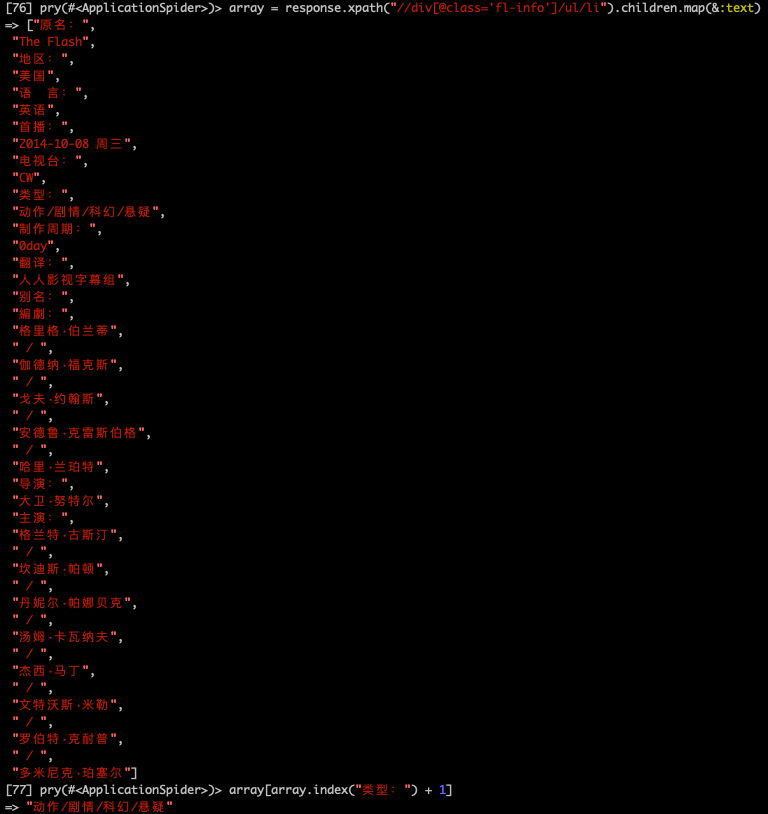
地区
方式同上
array = response.xpath("//div[@class='fl-info']/ul/li").children.map(&:text)
region = array[array.index("地区:") + 1]
# => "美国"
组图
response.xpath("//div[@class='resource-imgs']/div/ul/li/a/img").map { |img| img[:src] }

影视分级
img_url = response.xpath("//div[@class='level-item']/img").attr("src").value
File.basename(img_url).first

本站排名
response.xpath("//div[@class='box score-box']/ul/li").search("[text()*='本站排名:']").text.gsub("本站排名:", "").strip.split(" ").first
# => "15"
下载页面链接
未登录

登录后

登录需要配置cookies,先登录网站,然后通过开发者工具找到cookies的内容,填写到spider config里。

kimurai console模式目前只能传engine和url,所以需要配置之前的spiders/zimuzu.rb。
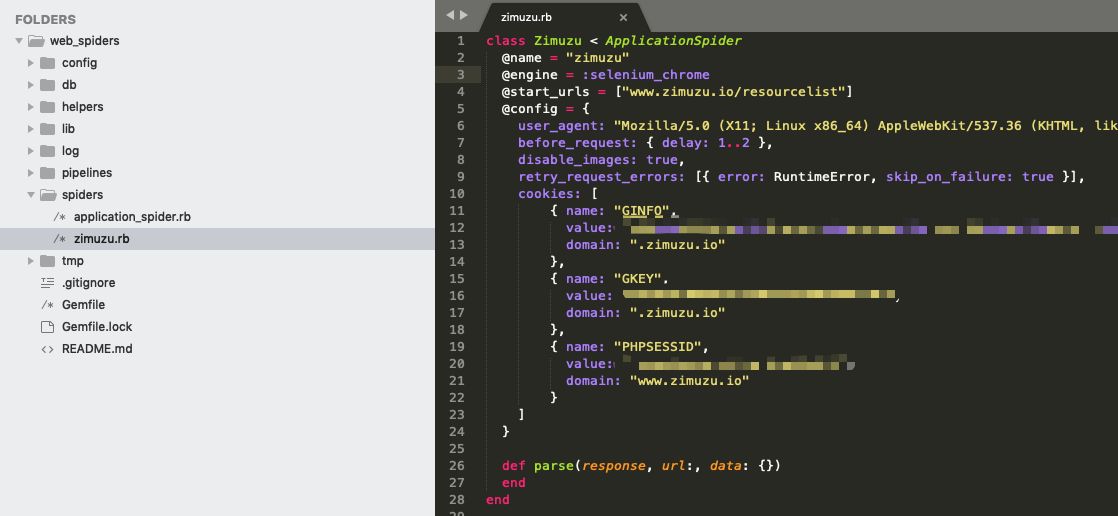
然后通过console调试这个spider。
kimurai console zimuzu --url http://www.zimuzu.io/resource/32235
最终获取到下载页的链接。
response.xpath("//div[@class='tc view-res-tips view-res-nouser']/h3/a").attr("href").value
# => "http://zmz005.com/LnPWY"
下载页

同样进入console模式,以MP4格式为例子,获取磁力链接。
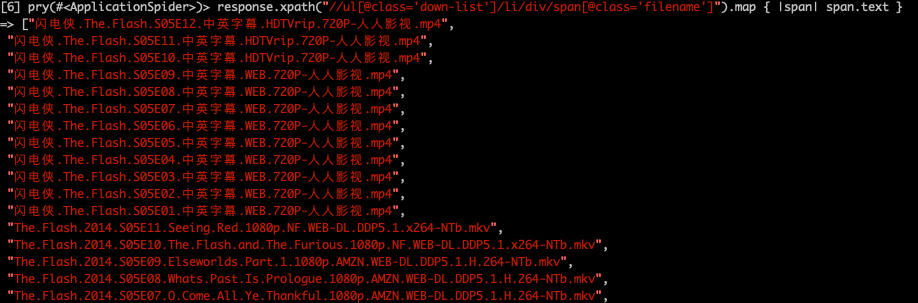
文件名
response.xpath("//ul[@class='down-list']/li/div/span[@class='filename']").map { |span| span.text }
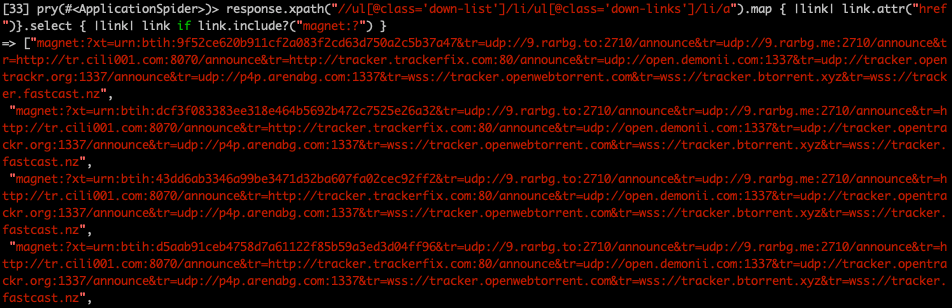
磁力链接
response.xpath("//ul[@class='down-list']/li/ul[@class='down-links']/li/a").map { |link| link.attr("href")}.select { |link| link if link.include?("magnet:?") }
编写爬虫文件
配置parse方法
def parse(response, url:, data: {})
urls = []
loop do
response = browser.current_response
# 详情页链接
response.xpath('//div[@class="resource-showlist has-point"]/ul/li/div[@class="fl-info"]/dl/dt/h3/a').each do |a|
urls << "http://zimuzu.io" + a[:href].sub(/ref=.+/, "")
end
# 下一页链接
next_page = response.at_xpath('//div[@class="pages"]/div/a[contains(text(), "下一页")]')
# 限制只获取前3页,方便测试
if next_page && Rack::Utils.parse_query(URI(next_page[:href]).query)["page"].to_i < 3
# browser.find(:xpath, '//div[@class="pages"]/div/a[contains(text(), "下一页")]', wait: 1).click #rescue break
# 根据官方的in_parallel介绍,使用element click触发跳转,抛出了以下异常
# Selenium::WebDriver::Error::UnknownError: unknown error: Element ... is not clickable at point (666, 303).
# Other element would receive the click: <div id="1548933432043_338366172" style="width:300px;height:302px;overflow:hidden;position: fixed;
# display: block; box-sizing: border-box; border: 0px; padding: 0px; margin: 0px; right: 0px; bottom: 0px; z-index: 2147483647; left: auto; top: auto;">...</div>
# 所以改用request_to方法,好处是无需关心下一页按钮是否可点击(有时会被其他元素覆盖,有时需要滚动条移动到按钮才显示)
request_to :parse, url: absolute_url(next_page[:href], base: url)
else
break
end
end
# 使用多线程方式
in_parallel(:parse_detail_page, urls, threads: 10)
end
配置parse_detail_page方法
def parse_detail_page(response, url:, data: {})
item = {}
item[:title] = response.xpath("//div[@class='resource-tit']/h2").children.first.text.gsub("【美剧】", "").strip
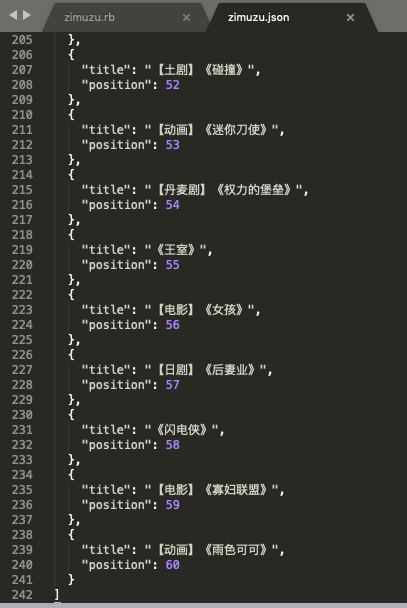
save_to "zimuzu.json", item, format: :pretty_json
end
测试爬虫
bundle exec kimurai crawl zimuzu

3页 * 20条 = 60条
完善属性及下载页数据
def parse_detail_page(response, url:, data: {})
item = {}
item[:title] = response.xpath("//div[@class='resource-tit']/h2").children.first.text.gsub("【美剧】", "").strip
item[:thumb] = response.xpath("//div[@class='imglink']/a/img").attr('src').value
categories = response.xpath("//div[@class='fl-info']/ul/li").children.map(&:text)
item[:categories] = categories[categories.index("类型:") + 1].split("/")
region = response.xpath("//div[@class='fl-info']/ul/li").children.map(&:text)
item[:region] = region[region.index("地区:") + 1]
item[:photos] = response.xpath("//div[@class='resource-imgs']/div/ul/li/a/img").map { |img| img[:src] }
level_img_url = response.xpath("//div[@class='level-item']/img").attr("src").value rescue nil
item[:level] = File.basename(level_img_url).first rescue []
item[:rank] = response.xpath("//div[@class='box score-box']/ul/li").search("[text()*='本站排名:']").text.gsub("本站排名:", "").strip.split(" ").first
item[:downloads] = []
downloads_page_link = response.xpath("//div[@class='tc view-res-tips view-res-nouser']/h3/a").attr("href").value rescue nil
# 访问下载页面,将文件名及对应下载链接拼装在一起
if downloads_page_link
browser.visit(downloads_page_link)
browser.current_response.xpath("//ul[@class='down-list']/li").each do |element|
text_array = []
link_array = []
element.xpath("div/span[@class='filename']").each_with_index do |span, index|
text_array[index] = span.text
end
element.xpath("ul[@class='down-links']/li/a").each_with_index do |link, index|
link_array[index] = link.attr("href") if link.attr("href")
end
item[:downloads] << { title: text_array.first, link: link_array.compact } if text_array.first && link_array.compact
end
end
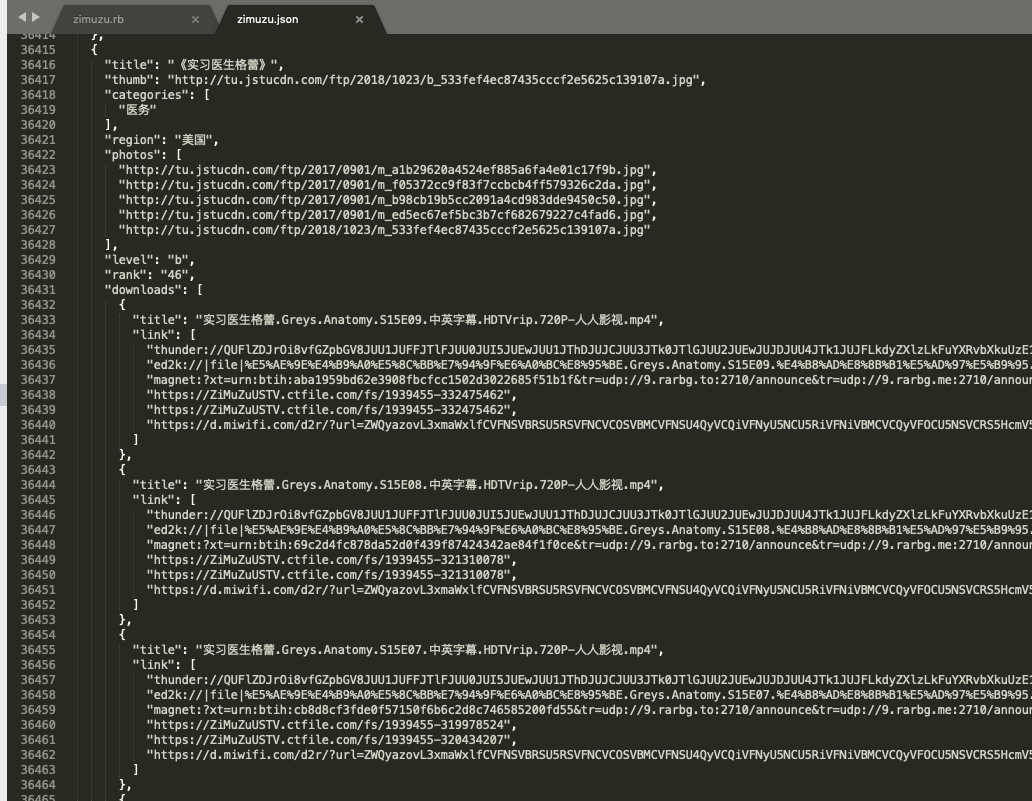
save_to "zimuzu.json", item, format: :pretty_json
end
将之前调试的所有属性和下载都完善好存入json,并再次执行爬虫。
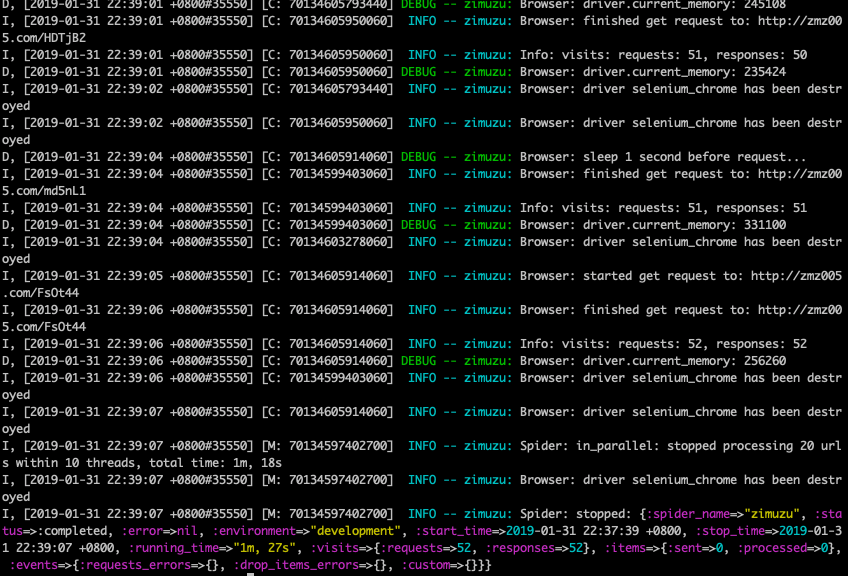
最终结果
想要深入的了解kimuraframework的更多功能,请看《Ruby爬虫框架kimuraframework实践(进阶)》



